01問い — 「出口さえ磨けば勝てる」は本当か
エントリーの研究に行き詰まると、多くのトレーダーは出口に希望を移します。「シグナルは変えずに、利確幅・損切り幅・トレーリングを最適化すれば、同じエントリーからもっと取れるはずだ」——。 これは検定できる主張です。そして検定するには、そもそもプラスの期待値を持つ確定エッジの上で試すのが公平です。土台がマイナスの手法に凝った出口を載せても、何も分かりません。
幸い、当研究所には現実約定(MT5 Strategy Tester)まで確認済みの確定エッジがあります——月曜朝の東京時間に円クロスを買い、固定60分で手仕舞うキャリー執行です。姉妹研究(R149)で「サイジング(増し玉・カット)は固定ロットが最適」と確認済み。残る未最適化の変数が、出口でした。
02設計 — 9通りの出口を「先に」登録し、PBOで裁く
出口の最適化には、致命的な罠があります。たくさんの出口を試して「一番良かったもの」を選ぶと、その勝者はしばしば「偶然その期間に良かっただけ」——本番では機能しません。これを避けるため、私たちは2つの規律を先に固定しました。
候補(事前登録・9通り):
早期固定 E_h30 / E_h40 / E_h45 / E_h50(30〜50分で手仕舞い)
利確+損切 E_tpsl_10_10 / E_tpsl_12_8 …(TP到達で利確・SL到達で損切り)
判定①:PBO/CSCV(訓練の勝者が検証で下位半分に落ちる確率)< 0.5
判定②:VAL 確認(IS選定後にのみ閲覧・Sharpe と PF が E0 比で向上)
エントリーは一切変えないので、全候補でトレード回数は同一です。「未約定で悪い日を取り逃して見かけ上良くなる」という逆選択は、構造的に起こりません。純粋に「出口だけ」を比べられる設計です。
03プラトーの誘惑 — 早く手仕舞いたくなる形
なぜ出口の最適化が「効きそう」に見えるのか。保有中の平均パスを見ると分かります。エントリー後、リターンは最初の30分で大きく伸び、その後(p30以降)はほぼ横ばい(プラトー)になります。
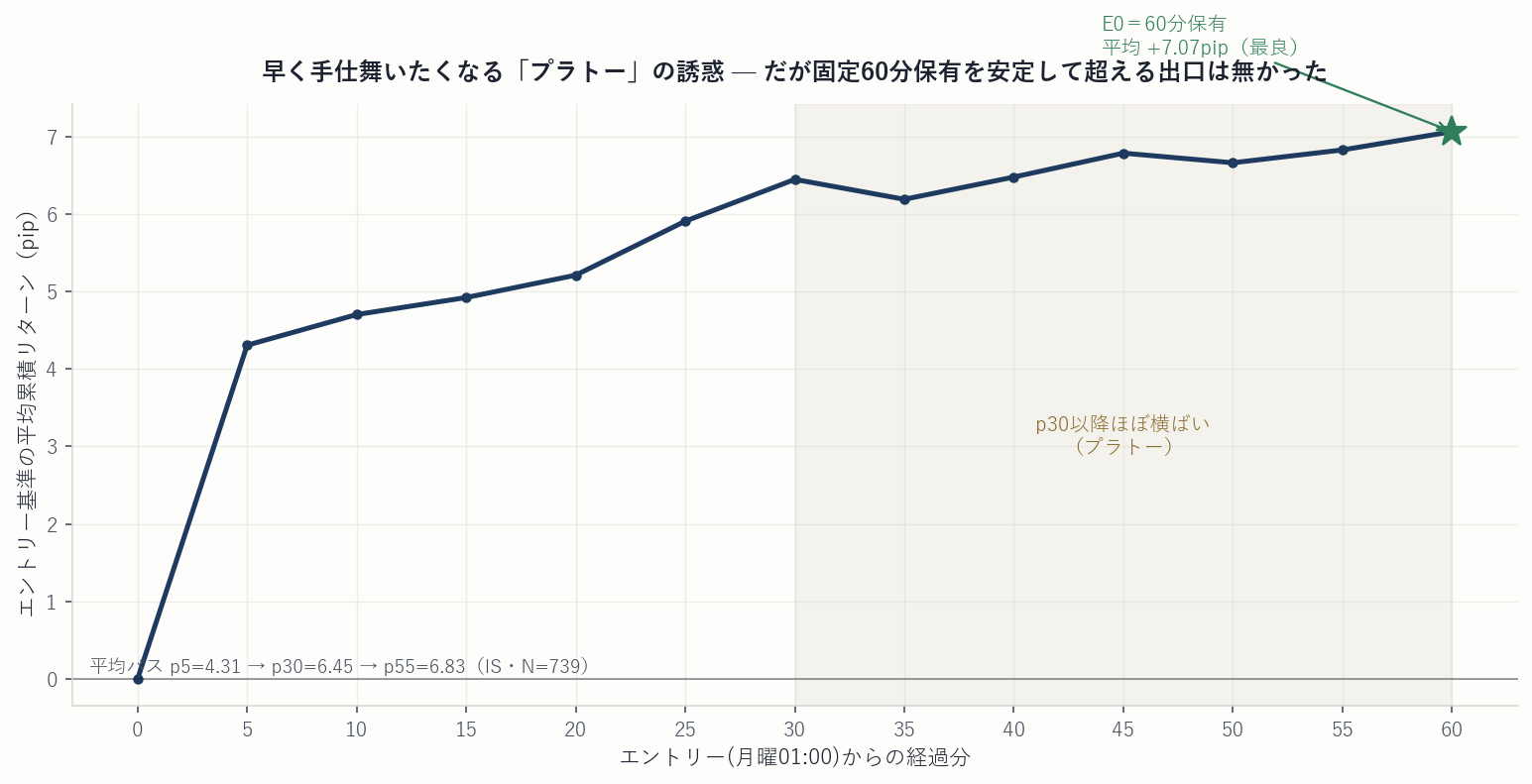
このプラトーが、出口いじりの誘惑の正体です。「30分でほとんど取り切っているなら、早く手仕舞ってリスクを減らせるはず」——直感的には正しい。しかし、その直感を9通りの出口で実際に検定すると、話が変わります。
04選ぶほど、外れる — PBO 0.726 と VAL逆転
候補たちの成績は、どれも僅差でした。訓練期間(IS)で最もシャープが高かったのは、利確+損切りの E_tpsl_12_8(Sharpe 0.343・固定保有E0の0.299をわずかに上回る)。一見、勝者に見えます。 ところが、独立した検証期間(VAL)を開けると——逆転していました。
| 出口 | IS Sharpe | IS PF | IS 最悪 | IS 最大DD | VAL Sharpe | VAL PF |
|---|---|---|---|---|---|---|
| E0(固定60分保有) | 0.299 | 2.51 | −128.7 | 376.1 | 0.529 | 4.27 |
| E_tpsl_12_8(IS最良) | 0.343 | 2.31 | −68.9 | 126.7 | 0.417 | 2.72 |
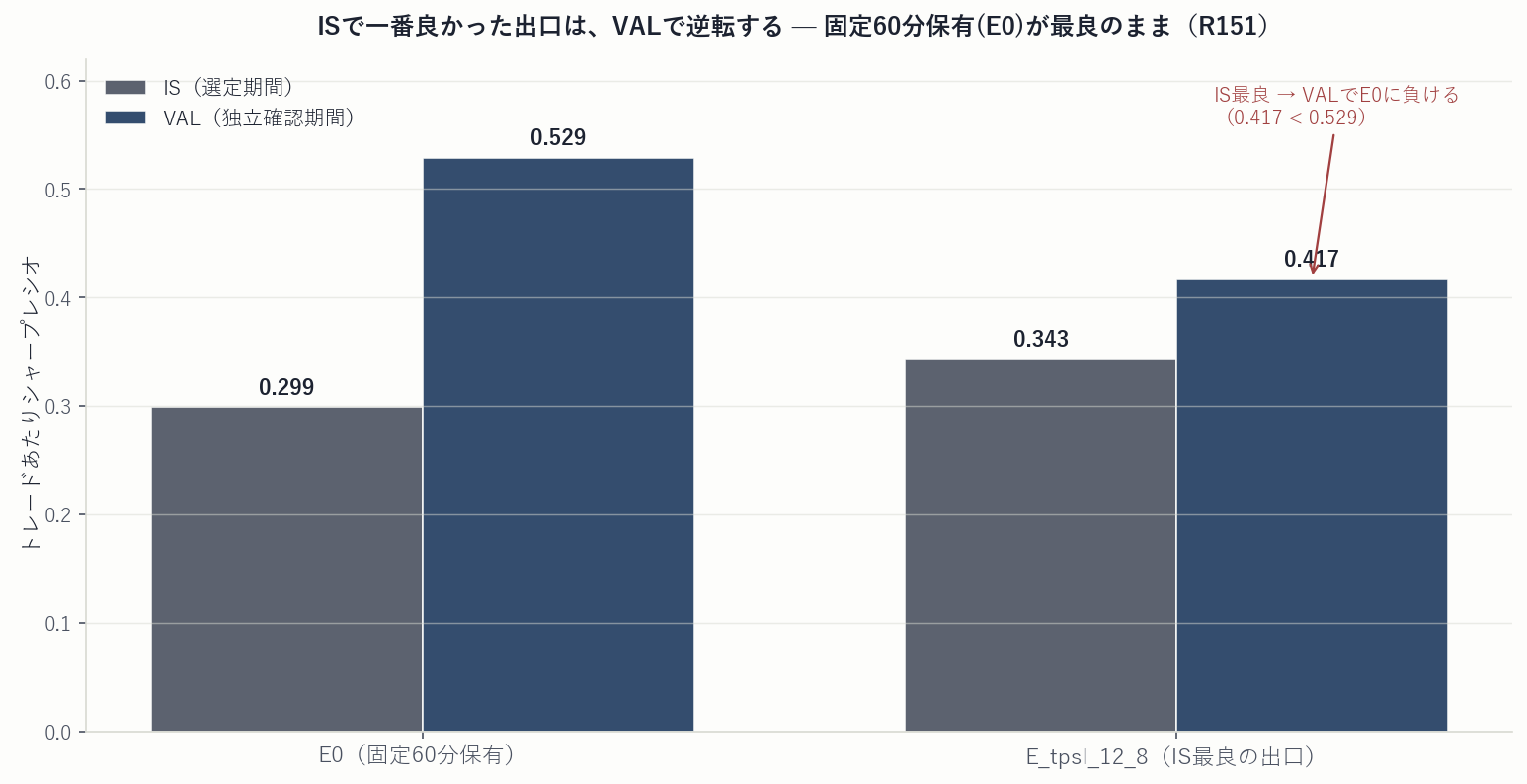
この「選ぶほど外れる」度合いを数値化したのが PBO(Probability of Backtest Overfitting) です。結果は0.726——訓練期間で選んだ勝者出口が、検証期間で下位半分に落ちる確率が73%。合格ライン(0.5未満)を大きく割ります。 つまり候補たちの差は実力ではなくノイズであり、「一番良い出口を選ぶ」という行為そのものが過剰適合を生んでいたのです。
「一番良かったものを選ぶ」が、なぜ危険か
候補が僅差で並んでいるとき、訓練データで首位に立つのは実力ではなく、その期間にたまたま噛み合ったノイズであることが多い。PBOは「その首位が別期間で崩れる確率」を測ります。0.726という値は、この出口最適化は情報ではなく雑音を選んでいたことの証拠です。AIや大量グリッド探索は、この罠をむしろ悪化させます。
05唯一「効いた」保護SLの、正体
ひとつだけ、明確に「効いた」ものがあります。保護的な損切り(−8〜−10pip)です。これは左の裾(最悪のトレード)を robust に切り落とします——最悪トレードは −128.7 → −68.9pip、最大ドローダウンは 376 → 127pip へ。数字だけ見れば劇的な改善です。
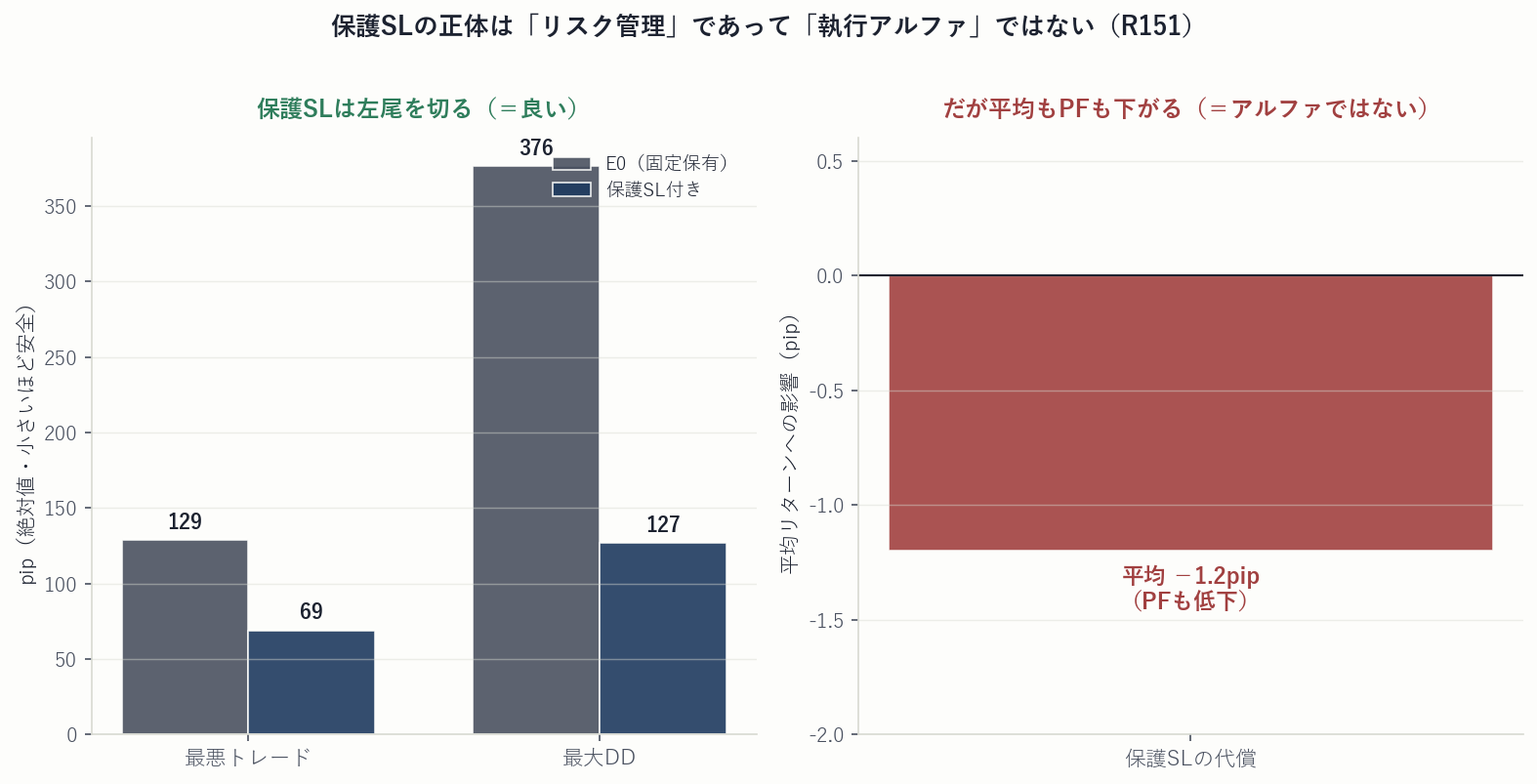
しかし、ここで立ち止まる規律が必要です。保護SLは左尾を切る代わりに、平均リターンを −1.2pip 犠牲にし、PFも下げます。これはリスク管理であって、期待値を上げる執行アルファではありません。 両者を混同すると、「ドローダウンが減った=改善した」と誤認してしまいます。損切りは資金管理・左尾保護の文脈では価値がありますが、「出口を磨いて勝てるようになった」という主張の根拠にはできません。
06結論 — 触らないことが、最良の執行だった
9通りの出口を事前登録し、PBOとVALで裁いた結論は明快です。この確定エッジの出口は、固定60分保有がすでに最適。安定してそれを超える出口は存在せず、勝者に見えたものは過剰適合、唯一効いた保護SLはアルファではなくリスク管理でした。 姉妹研究R149の「固定ロット・固定保有が最適」が、出口ジオメトリにも拡張確認された——つまりこのエッジは執行的にすでに near-optimal です。
示唆 — 「上位等級アルファ」は、執行いじりからは出ない
確定エッジの執行が near-optimal だという事実は、遠回りに重要なことを教えます。次の上位等級アルファは、既存エッジの出口最適化からは出てこない。それは、既存エッジのフォワード検証(実環境での先行運用)か、まったく新しいデータ軸にしかありません。「もっと磨けば」という誘惑を規律で断ち切ることも、研究の一部です。
研究KPI(経営指標・取引頻度に偏らない)
PBO / CSCV 0.726(要 < 0.5)=勝者選定はノイズ
byproduct 保護SL=左尾robust削減(リスク管理・アルファでない)
confirms 確定エッジは執行的に near-optimal(固定が最適)
score_band / gate_status / formal_grade 該当なし / FAIL(PBO+VAL) / Rejected
「もっと磨けば勝てる」を、多重検定で断ち切った研究も、同じ基準で公開しています。
当研究所は、訓練データの見栄えではなく、過剰適合確率(PBO)と独立検証で執行を判定します。 現実約定まで通過した検証済みプロダクトも、「これ以上は磨けない」と確認した研究も、同じ透明性で開示します。
検証条件: 対象=確定エッジ(月曜朝の円キャリー・4ペア・固定60分保有・現実約定 MT5 Strategy Tester 照合済み)の出口ジオメトリ最適化/ 候補=E0(固定60分)+早期固定(p30/40/45/50)+利確損切り(TP/SL)の計9候補/ 評価=保有中5分グリッドの前向きパス・エントリー不変ゆえ全候補N同一/IS=2020–2023(N=739)で候補選定・VAL=2023–2024(N=288)でIS選定後にのみ確認(peek-fit禁止)/ 勝者選定に PBO/CSCV を適用・コスト後・後知恵の候補追加は禁止(暗黙の多重検定)。 掲載した数値はすべてPython検証(記述統計・PBO/CSCV)の実測値です。本研究は既存確定エッジの執行検証であり、方向・時刻・採用ペアの詳細な発火閾値は保護のため本ページでは開示しません。
免責: 本ページは、確定エッジの出口最適化を多重検定で検証し「執行アルファ不成立(固定保有が最適)」と結論した研究ノートです。投資助言ではありません。記載はいずれも当社の検証範囲における結果であり、将来の利益を保証するものではありません。保護的損切りはリスク管理手法であり、期待値の向上を意味しません。FX取引には元本割れのリスクがあります。 図表はすべて実データ(保有パスのParquet/検証レポートの実測値)からのPython再描画であり、生成AIによる作画は含みません。